HOME
HOME 交通情報
交通情報
補聴器外来・耳鳴り外来


自分に合った補聴器を見つける旅
| 補聴器外来時間 | 診察の流れ | 当院の特徴 | 種類と値段 |
| いつから補聴器 | 医療費控除 | 各種助成制度 | 補聴器相談医 |
| 補聴器適合施設 | 補聴器技能士 | 認定専門店 | 補聴器の有用性 |
| 聴力改善手術 | 集音器/助聴器 | 耳の老化 | 補聴器事情 |
| 補聴器構造 | 耳鳴り治療 | 認知症治療 | 簡単聴力検査 |
| 未来の補聴器 | 途上国事情 | 世界の難聴 | 補聴器news |
月曜日と金曜日の午前部外来(AM10:00~PM12:00)予約制
補聴器の相談は、全日行っていますが、上記の時間帯以外は耳鼻科医師が担当します。
各種クレジットカード対応
まず耳鼻咽喉科医の診察を受けた後、補聴器外来です。
①難聴全般の診察及び相談
耳内の観察、既往歴、難聴をおこす病気の鑑別診断
②検査(当院は高度難聴指導管理施設)
聴力検査室で聴力の精密検査を施行。
③補聴器のフィッティング
聞き耳、聞こえ方、生活様式や金額等、患者様のご希望にかなった補聴器を選択
※障害者自立支援法による補聴器申請や各自治体の公的補助金制度にも対応
7つの理由
当院は医療機関なので、「その人にとり一番良い補聴器を探し出すこと」をいつも考えています。補聴器選定のために最高の知見を持っている医師が補聴器選びのお手伝いをすると、よいことがいくつもあります。当クリニックは公的に定められた高度難聴指導管理施設であり、院長の大場俊彦は学会認定の補聴器相談医です。また、聴覚領域の医療機器(補聴器・人工内耳・人工知能)の開発者としても世界的に有名です。世界各国に特許を申請し、日本でも特許を単独保持しております(JP3670180)補聴器に詳しい先生はたくさんいますが、米国で補聴器の特許を持っている医師は珍しいと思います。補聴器の中身まで知り尽くした医師があなたのために補聴器を処方するので安心です。
医師であれば、まず「その人の耳の調子がなぜ悪いのか」を考えます。単なる老年性難聴なのか、それとも中耳炎などの耳の病気が原因なのか、実はもっと重篤な病気が隠れているのか、きちんした診断をもとに選ぶことができます。外耳道は人によって形がずいぶん違います。耳鼻咽喉科の専門医であれば、鼓膜の奥まできれいに掃除して、耳の中のすべての状況を把握してから、その人の耳の形態に合った、最適な補聴器を処方することができます。当院での補聴器専門外来では新しく補聴器を購入される方のみならず、既に補聴器を購入したもののうまく使えない方、家に放っておいてずいぶん使っていなかった人への補聴器相談も行います。せっかく買った補聴器をうまく使いこなせないかたも、お気軽にご相談下さい。
当院の補聴器外来は、補聴器を購入するための外来ではなく、補聴器を適正に使用していただくための専門外来です。「補聴器がどういうものか見てみたい」、「使ってみたい」と思われている方もお気軽に相談していただきたいと思います。
居住している地域によっては、自治体が補聴器購入に補助金を出しているケースがあります。東京都中央区の区民に対しては、難聴に対する補聴器の購入について補助金が支給されます。東京都以外の地区の方々も自治体により補聴器の購入時に補助が出る場合があります。医師は地域のコミュニティーに属しているので、補助金についてはよく把握していますので、きちんと案内することができます。あなたに最適な補聴器を選ぶために、ぜひ当院にお越しいただければ幸いです。
補聴器の購入基準
| 名称 | 価格(非課税商品) |
| 骨導式ポケット型(両側) | 70.100円 |
| 骨導式眼鏡型(両側) | 120,000円 |
| 高度難聴用ポケット型(両側) | 34,200円 |
| 重度難聴用ポケット型(両側) | 55,800円 |
| 高度難聴用耳かけ型(片側) | 43,900円 [87,800円両側] |
| 重度難聴用耳かけ型(片側) | 67,300円 [134,600円両側] |
| 耳あな型:レディメイド(片側) | 87,000円 [174,000円両側] |
| 耳あな型:オーダーメイド(片側) | 137,000円 [274,000円両側] |
*補聴器は医療機器の為、消費税がかからない非課税対象商品
*補装具種目購入に要する費用の額の算定等に関する基準H18/9/29 厚労省告示528 9次改正H30/3/23厚労省告示121より抜粋
●補聴器の性能と価格
補聴器を選ぶとき大切なことは、いかに自分に合った聞き心地のいいものを選ぶかということです。単に様々な機能が付いていて何十万円もするものを選ぶのではなく、安くてもご自身が気に入った音質の補聴器を選んでご購入下さい。
音質の良い補聴器といえば、ベートーベンが使ったものが史上最高でしょう。耳の不自由な彼が数々の名曲を作り上げることができたのですから、よほど素晴らしい補聴器だったことが伺えます。彼の補聴器は、ピアノの上に置くラッパのような形をした巨大な筒形のものです。電気の無い時代ですので、筒を通して音を大きくするという単純な構造を用いたものですが、この技術を応用した米国ボーズ社は何十枚ものペーパーになる、ものすごい特許を持っているので、この簡単な原理に大きな活用の幅があることがわかります。ベートーベンの筒形補聴器は自然の法則を活用したものであるため、電気を用いて大きくした音より当然音質が良く、それを超える補聴器は現代にはまだ現れていません。耳の不自由な彼が補聴器の助けもあって偉大な業績を残したことを考えれば、現代人からしたら驚くくらい大きい補聴器であっても、それは取るに足らない問題なのです。
現代の補聴器の機能はほぼ全て同じくらいと思っていただいて構いません。では、値段ごとに何が変わるかというと、その大きさです。小さければ小さいほど高くなります。人工知能がついている? まあプログラミングがいくつかあると、人工知能ということになっています。その分だけやっぱり高くなります。
聴力の衰えというのは、実は20歳からすでに始まっています。「モスキート音」といえば若者にしか聞こえない音として有名ですが、年齢が上がるにつれて高い音から聞こえにくくなっていきます。
「カニ(蟹)を食べた」というのを「ワニ(鰐)!を食べたと」聞き間違えたり、デパートで声をかけられても、よくわからないという症状が、老人になると起こってきます。これは音が聞こえているのですが、周波数の分別がしにくくなって、言葉が聞こえなくなっているのです。これは全員に起きることです。聞き返しも多くなるでしょう。それもこのためです。去年まで耳の悪かったおばあちゃんが、今年になったら良くなったという話は聞いたことがないはずです。つまり耳の細胞は再生しないので、すべての人で難聴は加齢と共に確実に進行していきます。
これがさらに進行すると、人とのコミュニケーション能力が下がり、自分の殻に閉じこもり、痴呆症状が出やすくなります。聴力の程度にもよりますが、65歳前後が補聴器をつけるいい時期です。補聴器の操作は、少し複雑です。もっと高齢になると、使い方を覚えることがおっくうになり、使うこと自体を止めてしまうかたが多くなります。「このごろ少し聞こえにくい」、「聞きまちがいが多い」と思われる方は、まず御来院ください。

2018年から医療費控除の申請が簡略化され、また難聴に対しての補聴器の購入が、医療費控除(節税)の対象になりました。(社)日本耳鼻咽喉科学会頭頚部外科学会認定の補聴器相談医が診断後に、補聴器を購入した場合だけ、医療費控除(節税)が可能となります。重症の難聴があっても、お店での購入後は、一切控除されません。レンタルやリース方式による補聴器購入も、医療費控除の対象ではないです。補聴器の購入費が医療費控除の対象となる条件は、聞こえを補うということだけに使用するという目的ではなく、医師による診断治療の過程において直接必要とされて購入した補聴器の購入であることが必要です。 お店においては、購入したお客さんに対して、医療費控除ができない分、値下げするというお店があります。お店が、お客さんの耳の状態を医師に診断されたくないということです。このようなお店では、まず必要以上の高額な補聴器を買わされ、事故も起こす可能性も高まります。悪質なので注意しましょう。
**************
「補聴器購入の医療費控除:2018年度(H30年度)より変更」
高齢化の一途をたどる日本では、補聴器の需要は高まっています。しかし、補聴器は高い医療費がかかり、購入者にとっては大きな負担です。この負担を減らすことができるのが医療費控除です。支払った医療費が一定額を超えると医療費控除という所得控除が適用されます。日常生活で不可欠な義手/義足/松葉杖/義歯等と同様に、医師・歯科医師の診断を受けるのに直接必要なものであることが要件です。つまり、医療控除の対象になるには「医師による診断治療等の過程で直接必要とされて購入した補聴器である必要があり、単に自分の聴力を補うためにという目的に対しては控除対象外です。医療費は申請者の分だけでなく、生計を共にしている家族の分も認められる為、例として遠い実家の両親に仕送りをしている場合には、両親の分もまとめての申告が可能です。医療費控除は収入があれば家族のだれでも申告でき、控除額は所得の税率に従って増加し、家族内で収入の最も多い人が申告をするとお得な場合が多いです。また、以前と比べ医療費控除の手続きが簡単になりました。
◎医療費控除の算出法
その年の(1月1日~12月31日)の間に申告者本人または申告者と生計を共にしている配偶者、その他の親族に実際に支払った医療費が一定額を超えると、医療費の額をもとに算出された金額の控除を受けられます。未払いの医療費はそれを支払った年の医療費控除の対象です。医療費控除の金額の算出方法は以下の通りです。
(その年に実際に支払った医療費の合計額-①の金額)-②の金額
① 保険金等で補填される金額。尚、保険金は適応された医療費にかかるものなので、支給される保険金の額がその医療費を超えても他の医療費から差し引かれることはなし
② 10万円(年間の総所得が200万円未満の方⇒総所得金額の5%の金額)
◎確定申告の流れ
① 患者様(申告者)は(社)日本耳鼻咽喉科頭頚部外科学会認定の補聴器相談医を受診し、必要な診察検査等を受ける。
② 上記の補聴器相談医が記入した「補聴器適合に関する診療情報提供書2018」を受け取る。
③ 補聴器の販売店に行って②の資料を提出する。
④ 補聴器販売店で補聴器のフィッティングや試聴を行って自分に合う補聴器を購入する。
⑤ 補聴器販売店で②の写しと補聴器の領収書を受け取る。
⑥ 確定申告における医療費控除を申請し、それを保存する。税務署から求めがあった場合は提出する。
参考)詳しくは国税庁のHP
参考) 日本耳鼻咽喉科学会
国税庁HP「医療費控除の対象となる医療費」 [H29/4/1現在法令等]
国税庁HP「補聴器の購入費用に係る医療費控除の取扱いについて(情報)」[個人課税課情報第3号H30/4/16個人課税課]
補聴器自体は健康保険や生命保険では支給されません。2013/4/1に施行された、身体障害者福祉法を包括する「障害者総合支援法」第15条に基づいて、指定医による診断を受けた手帳保持者の場合には、難聴の程度に応じ補聴器支給を受けられる制度があります。補聴器の補助金は原則1割負担ですが、補聴器の種類や形式や基本構造によって基準額の上限が定められています。補助制度はお住いの地域により異なり、本人やご家族の経済の状況や納税の具合や身体状況等により、補聴器支給の対象にならない場合があり、まずはお住いの地区の福祉総合窓口でご相談下さい。また、当院の認定補聴器技能者はこれらの法律や制度に関するご提案をすることができますのでお気軽にお尋ね下さい。
「支給までの流れ(地域差あり)」
① 適合判定
耳鼻咽喉科で適合判定をする必要があります。補装具費用の支給が施行される条件は以下の基準を満たすと判定された場合です。
1)両耳 平均聴力LEVEL70dB以上
2)片耳 平均聴力LEVEL90dB以上、もう一方50dB以上
3)両耳による通常会話最良語音明瞭度が50%以下
② 手続き
適合判定で基準を満たした場合、本人お住いの市町村の福祉事務所・身体障害者福祉担当の窓口で補装具支給の手続きを行って下さい。
③ 発行・送付
手続き後に支給券・通知書の発行が行われ、その後、ご自宅に「補装具費支給決定通知書」と「補装具費支給券」が送付。
④ 購入
「補装具費支給券」を補装具業者に提出し、契約後に補聴器を購入可能です。
⑤ 請求
補聴器購入時の領収書を福祉事務所に提出して補助具費を請求可能です。
◎修理にかかる費用の補助
補聴器の修理が必要な場合においても上記と同様の手続きで補助金を申請可能です。尚、自費で購入された補聴器は対象外です。
東京都内の補聴器公的助成(区により異なります)
・東京都中央区
・東京都港区
・東京都千代田区
・東京都墨田区
・東京都台東区
・東京都葛飾区
・東京都江東区
・東京都大田区
(社)日本耳鼻咽喉科学会頭頚部外科学会認定補聴器相談医、通称「補聴器相談医」とは、学会の認定専門医で、補聴器に関する講習会に参加した耳鼻科医のみがなれます。慶友銀座クリニックの理事長の大場俊彦は埼玉県所沢市の国立障害者リハビリテーションセンター学院での研修に参加し、厚生労働省補聴器適合医師になり、日本耳鼻咽喉科学会認定専門医取得後、補聴器相談医になりました。近年国内での補聴器販売の実態は、補聴器の購入者が不利益を被るケースが多く報告され、早急な対応が必要であるとされました。
日本耳鼻咽喉学会は、難聴者が本人に合った補聴器を選んで使えるように、まず本人に補聴器の使用目的(聴力によって支障が生じているコミュニケーションの補完)を認識していただき、そして耳鼻咽喉科専門医のもとで適切な補聴器を購入するべきであるとしています。また、補聴器の販売者や従事者らは難聴者に適当な補聴器を選んで販売できるように、耳鼻咽喉科の医師の指導を受けるべきとしています。学会の地方部会において部会長や補聴器のキーパーソンや福祉医療委員や補聴器相談医の協力のもとに上記の事項を実現することで実態改善の実現を目指しています。日本耳鼻咽喉科学会(H16年理事会承認)では、補聴器販売の在り方に関する日本耳鼻咽喉科学会の基本方針で補聴器の販売業者に対し薬事法を遵守するよう指導しています。具体的には以下の事項があります。
① 管理者の設置
② 補聴器の品質の確保
③ 納品記録の作成
④ 消費者への適切な情報提供
⑤ 苦情回収
⑥ 身体障害者福祉法による補聴器の適切な交付
また、日本耳鼻咽喉科頭頚部外科学会は薬事法による公告の規制遵守を実現するべく耳鼻学会の指導を受けた販売業者を支援しています。
慶友銀座クリニックは、補聴器適合検査施設に該当しています。営利販売を主とする補聴器販売店とは異なり、難聴に対して高度な知識を有する専門医師が常勤し、補聴器を測定するための装置を保持しております。該当条件は以下です。
①耳鼻咽喉科を標榜している保健医療機関で、厚労省主催の補聴器適合判定医師研修会修了の常勤医師が1名以上配置。
②当該検査を行うのに欠かせない以下の装備・器具を常備。
・音場での補聴器装着実耳検査に必要な装置や機器
・騒音、環境音や雑音等の検査用音源または発生装置
・補聴器周波数特性測定装置
補聴器は医療機器です。医療機器を扱うには、医師とともに認定技師(認定補聴器技能士)又は音声言語聴覚士が扱うのがふさわしいです。
認定補聴器技能士とは公益財団法人テクノエイド協会が実施する最短5年の厳しい認定補聴器技能者養成課程を修了した最終試験の合格者が認定されます。対象となる条件は厳しく、まず3年以上の実務経験があり日本耳鼻咽喉科学会の専門医から指導を受けているものが最初の基礎講習の対象となり、耳鼻科専門医との連携を更に2年取っていることが条件です。認定補聴器技能士は高度な専門知識だけでなく、難聴者のコミュニケーションの改善方法や補聴器のフィッティングの計画の立案、そして実践をこなす幅広い知識・技能を持ち合わせています。
慶友銀座クリニックの補聴器外来には、ベテランの認定補聴器技能者がいます。補聴器担当医師と連携して補聴器のフィッティングを行います。又医療費控除の説明やお住まいの地域に応じた公的支援関連のアドバイスも行います。
老人人口が増えて、補聴器を取り扱う業者も増えてきました。特にメガネ専門店が、格安眼鏡店が台頭してからか、業務形態転換として補聴器を取り扱うことも多くなりました。耳鼻咽喉科医は、眼科のことはよくわからないのに、メガネの専門家が補聴器を簡単に扱うことには違和感があります。また家電量販店やデパートもポイントや値引きでかなりの数の補聴器を販売します。このような形態の補聴器販売店での販売者の多くは、4時間弱の簡単な講習で修了した方です。受講資格は、適切な補聴器の選定や使用指導を目指す補聴器販売従事者なので、補聴器を販売していれば経験問わず、学歴問わず、資格問わずです。
参考 日本補聴器販売店協会 補聴器販売者技能向上研修
認定補聴器専門店とは、公益財団法人テクノエイド協会(東京都新宿区神楽河岸)認定の補聴器の使用指導するために必要な知識と技能を兼ね備えたものが常駐しており、補聴器の調整や効果の確認をするための設備が整っており、補聴器相談医と連携して業務を行っている補聴器販売店です。
補聴器というのは難聴者にとっては欠かせない重要な医療器具であり、選択の際、学会認定の耳鼻咽喉科専門医である補聴器相談医のいる場所で、診断してもらったうえでフィッティング及び購入するのが望ましいです。もし補聴器を選び間違えることがあると、難聴者が事故を起こしてしまったり、難聴の治療時期を逃したりしてしまうことが考えられます。補聴器の購入前には必ず「補聴器相談医」の診察を受けましょう。
(社)日本補聴器販売店協会(東京都千代田区内神田)からのお話を追加します。 難聴の方が、「最近、聞こえが悪くなった」と感じ、補聴器店に訪れたとき「 補聴器を合わせる」より先に「診断と治療」が必要な場合があります。このような場合は、できるだけ早い状態で、診断治療を受けることが望ましいです。まずは耳鼻咽喉科専門医である補聴器相談医に受診することを勧めることが大切です。せっかく来院したお客様に、補聴器を販売する前から「医療機関で診察を受けて下さい」とお願いすることは、補聴器販売店としてはなるべくしたくないと思うかもしれません。(耳鼻咽喉科医としては、補聴器をつける前は、診察するのは当たり前だと思いますが…)、しかしながら、これを怠った、難聴治療の時期を逃がしてしまったり、事故を起こした場合の責任はとても重大です。補聴器という医療機器を取り扱う者には、補聴器の販売前に専門医に診察を受けてもらうようにお願いすることを遵守する義務があります。
| 伝音難聴 | 感音難聴 | 混合性難聴 | |
| 障害部位 | 外耳・中耳 | 内耳・蝸牛神経・脳 | 外耳・中耳・内耳・蝸牛神経・脳 |
| 治療 | 治療(手術含め)により症状が改善する可能性有 | 早期に治療すれば改善する可能性も | 伝音部分を治療すれば改善の余地があるが、感音部分は早期治療が必須 |
| 症状 | 音が小さく聞こえる | 音がひずみ、言葉等がはっきり聞き取れない | 音が小さく聞こえ、はっきり聞き取れない |
| 原因疾患 | 滲出性中耳炎、鼓膜穿孔、耳小骨連鎖不全、外耳道閉鎖 | 加齢に伴う難聴(老人性難聴)、突発性難聴、騒音性難聴、遺伝性難聴 | 慢性中耳炎 耳(鼓室)硬化症 |
| 補聴器有用性 | とても役に立ち、ほぼ正常なきこえに近づく | 役に立ち必要だが、完全に正常な聞こえにはならない | 伝音難聴と感音難聴の中間 |
慶友銀座クリニックには、耳の診断に欠かせないコーンビーム型CTがあり、その場で撮影し診断可能です。また慶應義塾大学耳鼻咽喉科所属の耳手術の専門医師(准教授・講師・部長)が当院に4名在籍し、大学病院及び関連病院(慶応病院・東京都済生会中央病院・日本医科大学病院)にて手術を行い、当院でフォローアップを行っています。大学病院で長い時間待たされてへとへとになるのであれば、当院に受診すればへとへとになる前にベテラン医師が診断し、今後の治療方針についてお話が可能です。
① 伝音再建手術(鼓室形成術・アブミ骨手術・外耳道形成術)
耳硬化症や慢性穿孔性中耳炎・中耳真珠腫等の炎症性難聴病態の多くは、手術により聴力改善は見込めます。
② 骨導インプラント術
③ 人工内耳VSB
④ 残存聴力活用型人工中耳EAS
⑤ 人工内耳
実は補聴器を使う人の一番の問題は、電池の交換の手間です。老眼の方にとっては、補聴器の小さな電池の入れ替え作業は大変です。現在では充電型の補聴器も出てきました。スマホを毎日充電するように、補聴器も充電するのです。一見、補聴器のような「集音器」「助聴器」と呼ばれるタイプは安く売られていますが、このタイプのモノは当然補聴器と比べれば機能は低いですし、電池代が非常に高くつくようです。きちんとした補聴器を作った方が結局は経済的に安くすむでしょう。
耳の老化は30代より始まって、聴力の衰えは50代から生活に支障が出て、自覚することが多いです。同じように加齢による老眼と比較するとおざなりになっていることがよくあります。鼓膜からの振動で増幅された音が、鼓膜の奥の内耳にある蝸牛という渦巻き状の管に生えている有毛細胞でキャッチされて、電気信号に変換されて脳に伝導します。加齢で、この有毛細胞が傷ついて、壊れてしまいます。傷ついた有毛細胞は、再生能力がないので、生き返ることは不可能です。特に哺乳類の有毛細胞は再生せず、鳥類は再生します。このような研究を大学院時代に私は行ってきました。(下記 参考文献参照)加齢性の難聴になると、周波数の高い音から順に聞こえにくくなります。外来診療において、携帯電話の着信音が聞こえないとかで来院する患者さんの場合は、まず加齢性難聴を考えます。加齢性の難聴の患者さんは、子音の聞き間違いが増えるとされています。寿司=串=牛など同じように聞こえるという患者さんもいます。これは高い周波数で構成されているサ行・カ行の音が聞き分けにくくなります。 TVで若手のコメディアンが言っていることがよくわからないという訴えもあります。これは若いコメディアンに多い早口に追いついていないということを意味します。聞こえのルート(耳から脳へと伝わる聴覚伝導路)で処理するスピードが加齢によって遅くなることが原因です。昔みたいに100mを全力疾走しても、若かりし頃のスピードには及ばないことで、このことはよくわかると思います。聞きやすい音の範囲も狭くなってしまい、一定のレベルを超えた大きな音もうるさく感じます。これらのことは、私は、老人になると行動範囲も狭くなり、老人になったり疲れたりすると結構怒りっぽくなるのと一緒と患者さんに比喩的に説明しています。大きな音に長時間さらされると、有毛細胞を痛めてしまうので、騒音環境下の仕事や長時間で大音量で音楽を聴くことを長年行っていると、将来耳に不自由がおこることが多いです。会議でまわりが何言っているかよくわからないという患者さんも多いです。会議室はまわりの雑音もなくいい環境ですが、音が響くような高級会議室だと、発した言葉も響いて時差で耳に届くため、脳での処理が複雑になってしまい、聴きづらくなります。加齢性の難聴を悪化させる原因として、まず糖尿病があります。他に高血圧・肥満・脂質異常・動脈硬化・喫煙・飲酒があります。動脈硬化や高血圧等の生活習慣病では、内耳や脳の血流が悪くなり、聞こえの機能を悪影響を及ぼすと考えられています。喫煙やアルコールは動脈硬化や高血圧の悪化に関係します。難聴が悪化していく場合は、遺伝性難聴を疑います。19種類の聞こえに関係する遺伝子を血液検査で調べることができ、保険適応となります。当院ではこの検査は関連病院にて行っています。 職場の平均年齢が高齢化している現代では、難聴を抱えながら働いている方も増えています。米国では軽度の難聴でも補聴器を付けて、現役並みに働くことが一般的で、第42代クリントン米国大統領も補聴器を装用していました。彼は日本のどの総理大臣と比べてもキレがあり、問題解決能力に長けた大統領であったと思います。難聴でも補聴器を付ければ健常者にも決して劣らないパフォーマンスが発揮できるという良い例です。
参考文献
Heterogeneity of Phospholipase C in the cochlea of of the Guinea pig:Oba T. Ogawa K.et.al.
https://www.karger.com/Article/Pdf/55757
日本における補聴器の実態調査
調査主体:一般社団法人 日本補聴器工業会 後援 :公益財団法人 テクノエイド協会 協力 :EHIMA (欧州補聴器工業会) JapanTrak 2018 調査報告
男女共に、65歳を超えると難聴者の比率が高まり、 75歳を超えると補聴器所有者の比率が高まる傾向が見られる。75歳以上の男女とも8%が補聴器装用者である。
補聴器所有者の両耳装用率 : 45%
最近の補聴器をめぐるトラブルはなんですか?
今現在、補聴器は様々なところで売られています。メガネ屋、電気店、通信販売などでも気軽に変えます。一見安く売られているようでも、実際には価格差はほとんどありません。それに関連して補聴器をめぐるトラブルも増えています。近所の補聴器屋さんや眼鏡屋さんで購入したけど、実は鼓膜に穴が開いていた(耳鼻科以外の医師では鼓膜の診察を正確に行うことはまず無理です)。左右一括購入を勧められ安くなったけど、買った後うまく調整してくれない、調整するのに多額の費用がかかる。補助金使えるのに教えてくれなかった(お店が医療機関に紹介するのが面倒くさい)。老人会で知り合いから買ってくれとせがまれたとかいう、よくわからないものもあります。難聴で補聴器を希望して来院する患者さんの中には、治療で良くなる難聴もあり、耳鼻科医だけが診断し治療できます。
難聴で当院を受診された方で、どう見てもよい耳に、高額の補聴器をつけられている方がいらっしゃって驚きました。笑い話のようですが、本当の話です。素人の店員さんしかいない補聴器取扱店で補聴器を買うと、このように聴力に問題のない耳に補聴器をつけてしまうなんてことも、しばしば起きるようです。補聴器は資格がなくても、メガネ店や電器店などで普通の人が売ってもよいとされている商品です。ですから、話を聞きながら勧めてくれる店員さんの経験値も、店舗の形態もさまざまです。つまり、補聴器は買い手の側が気をつけないと、たいへんな目に遭うかもしれない高額な買い物なのです。
| 医療機器分類 薬機法(2014/11) |
定義 | 医療機器例 | 認許可区分 |
| 一般医療機器 ClassI |
不具合が生じた場合でも人体への影響が軽微 | 聴診器 メス | 届け出 |
| 管理医療機器 ClassⅡ |
人の生命の危険または重大な機能障害に直結する可能性は低い | 補聴器、電子血圧計 | 承認または認証 |
| 高度管理医療機器 ClassⅢ |
不具合が生じた場合、人体への影響が大きい | 人工内耳、透析機器 | 承認または認証 |
| 高度管理医療機器 ClassⅣ |
患者への侵襲性が高く、不具合が生じた場合、人の生命の危機に直結するおそれ | ペースメーカー、冠動脈ステント | 承認 |
2017年7月国際アルツハイマー病会議 AAIC で、ランセット国際委員会が認知症症例の約35%は、潜在的に修正可能である9つの危険因子に起因していると発表しました。難聴は、高血圧・肥満・糖尿病等とともに、9つの危険因子の一つに挙げられています。その際に予防できる要因の中において、「難聴は認知症の最も大きな危険因子」という指摘がされました。日本においても、2015年1月に、日本政府が急速な高齢化である日本の問題において、「認知症対策強化」に向けての、国家戦略「新オレンジプラン 認知症施策推進総合戦略」を策定しました。日本国として、認知症の発症の予防推進と、認知症を罹患した高齢者の日常の生活を支える仕組みのづくりに取り組みました。その中において、認知症危険因子として、加齢・高血圧等とともに、難聴が取り上げられました。
●Dementia prevention, intervention, and care: 2020 report of the Lancet Commission The Lancet J
●認知症施策推進総合戦略(新オレンジプラン)厚生労働省
P社作成のモスキート音を使った「聞こえチェック」です。耳年齢の参考にしてください。
院長の大場俊彦が保有する補聴システムに関する発明の内容です。補聴器の未来が書かれています。簡単な内容としては、従来難聴者に対して補聴器は音を大きくさせるだけであり、音声情報の意味内容を把握するためには不十分でした。また全ての音を増幅して提供するので、補聴器を使っている人は、音声情報以外の雑音が気になる人が多かったです。入力された音声に対して、音声認識と音声要約と音声合成を使う補聴システムを考案しました。音声認識と音声合成を使うことで、雑音がカットされることにより、語音明瞭度が改善されます。また音声要約をすることで、音声情報自体が少なくなることにより、音声情報の意味内容がより把握されやすくなることが期待されるという特許です。
被引用特許というものがあります。これはある特許が通る課程で、日米の特許庁が、「あなたの出した特許は、この特許と考えが似ているから変更しなさい」と指示することがあります。簡単に言えばこれを被引用特許と言います。大場俊彦が出した特許は、医療関係では、人工内耳のトップシェアを誇るコクレア社(2件)、他には米国IBM(2件)・バンク=オブ=アメリカ(MITメディアラボでの研究に関連含む:7件)・三菱電機(1件)等の世界的な起業が出した特許よりも日米の特許庁より先進性が認められました。それらの会社が出した特許は、大場俊彦の発明した補聴システムの先進性のため変更を余儀なくされ、回避して出願したという経緯があります。下記をみると、補聴器の特許なのに、なぜ銀行やコンピューター会社が出した特許がでてくるのかと思われるでしょう。補聴システムは米国で音声装置で出願しています。未来の銀行の窓口業務では、窓口の女性がコンピューターにかわるとのことです。音声システムは、世界の銀行の窓口業務の標準となるIBMが開発したワトソンという人工知能にとり必要不可欠なシステムです。院長の考えた難聴者のためのシステムが、人工知能の銀行業務に関係するようになります。
バンク=オブ=アメリカの特許
US9138186 Systems for inducing change in a performance characteristic
US8715178 Wearable badge with sensor
US8715179 Call center quality management tool
US9138186 Systems for inducing change in a performance characteristic
US20110201899 Systems for inducing change in a human physiological characteristic
US20110201959 Systems for inducing change in a human physiological characteristic
US20110201960 Systems for inducing change in a human physiological characteristic
米国IBMの特許
US20130226576 Conference Call Service with Speech Processing for Heavily Accented Speakers
US8849666 Conference call service with speech processing for heavily accented speakers
三菱電機の特許
US8990092 Voice recognition device
コクレア社の特許
US8170677 Recording and retrieval of sound data in a hearing prosthesis
US20070027676 Recording and retrieval of sound data in a hearing prosthesis
発明の名称 補聴器 発明者・考案者 大場俊彦 出願番号 特願平11-338458 1999/11/29 国際出願番号 公開番号 特開2000-308198 2000/11/02 公表/再公表番号 国際公開番号 公告番号 請求公告番号 登録番号 特許第3670180号 2005/04/22 米国特許US Pat 7,676,372 Link http://www.google.com/patents/US7676372
JETROの報告では、インド都市部の93%、農村部の55%が電化されています。しかし需要が供給を超え、農村部において一人当たりの電力の消費量が非常に少ないとのことです。大部分の農村部において、一日にたった数時間のみの電気供給で、途中で停電・電圧低下が起きているとのことです。インドの全体の電化率は、63%で、残りの37%は電気のない生活を送っているとのことです。新型コロナ感染症蔓延・ロシアウクライナ状況によるエネルギー需要変化や石炭の不足にて、インドを含めた世界的な電力不足になっています。
特にインドを含めた南アジアを筆頭に、補聴器を必要とする難聴者は増大中ですが、上記に述べた発展途上国における劣悪な電力環境及び医療の資源不足によって、補聴器の普及はせず、治療を受けられていない難聴者は増大して、経済的損失も増大しているとのことです。
JICAが日本補聴器製造販売メーカー「リオンKK」と共同で行った、インドの農村地帯における補聴器の販売調査では、インドは現在経済発展が著しいのですが、都市部と農村部の経済の環境はかなり乖離し、上記にも書きましたが農村部における深刻な電力の不足や劣悪な医療において経済と生活の環境と、他の発展途上国との状況がにていて、発展途上国における難聴の対策について参考になります。日本では通常医療用の補聴器としてほとんど販売されていないアナログ式の耳かけ型の補聴器(約1万円片側)が主に購入されたそうです。現在の聴覚医学の研究では、30年前から普及してきたデジタル式補聴器が主流(約20万円片側)であり、難聴改善の満足度が低い廉価型のアナログ補聴器では結局継続性の低下が懸念されます。
●Guidelines for hearing aids and services for developing countries September 2004,
●インド ニューデリーBOP実態調査レポート 電力事情 JETRO2013
●インド国 農村部における聴覚診断網の確立 及び補聴器販売事業準備調査 (BOP ビジネス連携促進) 報告書 2016年 独立行政法人 国際協力機構 (JICA) リオン株式会社 株式会社 WIA Lab
2018年3月に世界保健機関WHOは、高齢者の人口の増大等で世界的に聴覚障害に苦しむ人が増加し、2050年に現在の推計約4億7千万人から9億人に達する可能性があると発表しました。WHOによると、5年前には聴覚障害に苦しむ人の人数は3億6千万人でしたが、2018年の推計値は4億6600万人、その中で3400万人が子供とのことでした。WHOは、麻疹等の感染症の予防や難聴を引き起こしてしまう可能性のある薬物を使用しない、職場・屋外において大音量の音を出さない等の対策を取ることにより、聴覚の障害の半数は防げると指摘して、各国の政府に適切なる対策を取るよう求めました。対策を取らない場合は、治療等のコストを含めた経済的損失は全世界で年間7500億ドル(80兆円)と報告しました。高額な補聴器を購入することが可能な高収入の人々がいる国の人数の比は、全世界難聴者の0.1%との報告があります。世界的には大部分の人は、耳の専門家から医学的に適切に処方された補聴器を買うことは経済上では難しいです。難聴は放置してしまうと、子供の場合言語の習得の遅れよりコミュニケーションの能力や学業の面に影響が出て、成人の場合職業の面に影響が出てきます。発展途上国において、難聴をもつ子供がしっかりとした学校の教育を受けることは滅多になく、また難聴である成人就業率も非常に低いとのことです。地域別難聴者の人口比率として、南アジア地方(インド等)が約30%弱、東アジア地方(インドネシア等)約22%、アフリカのサハラ砂漠以南地方(アフリカ全体の8割の人口)が約10%です。地域別に多い南アジアでは、2008年の難聴者数は2050年では、2.5倍に増大するそうです。補聴器は電気機器でもあるので、高額で煩雑な電池の交換が必要で、最近では充電式が普及しています。
●Addressing the rising prevalence of hearing loss Feb 2018,WHO
●World report on hearing WHO 2020
◎2023年6月6日は補聴器の日です。
◎2023年度第124回日本耳鼻咽喉科頭頸部外科学会総会が5月17日~20日まで福岡市で開催補聴器関連の発表も多数 院長出席
◎日本耳鼻咽喉科頭頸部外科学会補聴器相談医資格更新の為の講演会(東京)を院長が受講しました。2022年7月12日
◎瑶子女王さまが、感音難聴であることを令和4年3月の講演で明かしました。朝日新聞デジタル 2022年6月24日
◎2022年6月25日に介護の未来をテーマとしたシンポジウムが富山市で開催されました。
東京大学の本田先生他が参加し、寝たきりの人が補聴器をつけることで活動的になった事例を紹介しました。
◎「補聴器の適正広告 表示ガイドライン第四版 (社)日本補聴器工業会 (社)日本補聴器販売店協会」2022年5月20日に発令しました。今回の改訂において、医薬品等適正広告基準と、基準の解説と留意事項(H29)に則して、新製品の表示を6ヶ月より12ヶ月へ修正し、特定電子メール送信の適正化等に関する法律を反映させました。
参考 https://www.jhida.org/pdf/kensyo/koukokuguideline_4th.pdf
◎東京都中央区からのお知らせです
中等度難聴児発達支援事業(補聴器購入費助成)
身体障害者手帳の交付対象とならない中等度難聴児に対して、補聴器の購入費用の一部を助成します。
対象:区内在住の18歳未満の児童で、次の要件を全て満たす方
・身体障碍者手帳(聴覚障害)甲府の大将となる聴力ではない方
・両耳の聴力レベルがおおむね30デシベル以上であり、補聴器の装用により、言語の習得などの一定の効果が期待できると医師が判断する方
●既に購入された商品については助成対象となりませんのでご注意ください。
●所得要件があります。申し込み方法など、詳しくはお問い合わせください。
障害者福祉課相談支援係
電話:03-3546-6032 FAX:03-3544-0505
◎2022年6月6日は補聴器の日です。6を向かい合わせると耳の形になり、耳の日が3月3日でx2で6月6日ということです。補聴器販売店の団体である(社)日本補聴器販売店協会(東京都千代田区内神田二丁目11番1号)と補聴器メーカーの団体である日本補聴器工業会(東京都千代田区内神田一丁目7番1号)が6月6日を補聴器の日と制定しました。
◎2022年5月25日~28日に神戸ポートピアホテルにて日本耳鼻咽喉科頭頸部外科学会総会学術講演(123回)が行われます。この学会では難聴者・聞こえない人を対象とした補聴器を含む研究発表の日本で一番大きな学会です。
◎2022年10月5日~7日 日本聴覚医学会総会 山形テルサ:日本聴覚医学会では難聴者・聞こえない人の補聴器を含む主に臨床研究を行っています。
◎2022年10月19日~21日 日本耳科学会総会開催 主催 山岨達也(東京大学耳鼻咽喉科学教室) 場所 パシフィコ横浜ノース 神奈川県横浜市西区みなとみらい:補聴器の装用は難聴者にとって非常に重要です。日本耳科学会では難聴者 聞こえない人の補聴器を含む基礎研究を行っています。
◎2021年10月20~22日 第66回日本聴覚医学会総会学術講演会 会場 昭和大学上條記念館 東京都品川区旗の台1-1-20 が開催
◎2021年10月13~16日 第31回日本耳科学会総会学術講演会 会長 小島博巳 東京慈恵会医科大学 会場 ヒルトン東京お台場 東京都港区台場1-9-1にて開催
◎消費電力が低くなる装置で将来的に補聴器の電池交換の頻度が減るかも。EETimes Japan 2021/8/6
エ社は7/6に動作時消費電流MAX990nAと、とても低い1セルBattery保護ICを販売。これで補聴器等に搭載のリチウムイオン(2次電池pack)、リチウムポリマー(2次電池pack)に将来的に使われる。
◎重機事故(大阪)巡る裁判で、死亡した女子児童の遺族は障害者差別は絶対に許せないと訴え2021/7/14 読売テレビ:争点は損失利益。聴覚支援学校に通う女子児童の聴覚障害を理由に賠償額の減額を被告側は主張。遺族側は差別は許せないと訴え。事故を起こした会社側は、死亡した児童は難聴の為に思考力が低く、正社員での就職困難等とし一般的な女性の40%まで減額を主張。遺族側は補聴器を装用すれば会話可能であったので収入に差はないとの主帳。
◎先天性難聴の主将エース完投(7/10高校野球静岡大会)朝日新聞デジタル2021年7月11日
◎日本耳科学会総会学術講演会(31)が開催予定。会期2021/10/13〜16 会長小島博己 (東京慈恵会医科大学 耳鼻咽喉科)会場;ヒルトン東京お台場 東京都港区台場1-9-1
◎(社)日本聴覚医学会(理事長 東京大学医学部耳鼻咽喉科山岨教授)の総会学術講演会(66回)は、昭和大学医学部耳鼻咽喉科学講座主催でR3/10/20- 22 昭和大学上條記念館(東京都品川区旗の台1丁目1の20)開催
◎R3/3に神奈川県大和市議会にて「加齢性難聴者の補聴器の購入に公的な助成を求める」陳情書が提出。国に対し加齢性難聴者の補聴器の購入に公的な助成を求める意見書を上げる、国に対し特定検診の項目に聴力検査を入れるように上げる、市独自に助成する制度を検討する等の項目が入っていました。
◎東京オリンピックに続いて催される東京パラリンピックには聴覚障害者の競技がなく、増大する費用が関係する。代わりに国際聾者スポーツ競技大会(現デフ・リンピック)が国際大会としてあり日本からも大勢の選手が参加。
◎マスクの日常化で聞こえにくいとのことで、補聴器の需要アップ 読売新聞ONLINE 2020/10/15 新型コロナの感染の防止のためマスク着用が必須で、高齢者・難聴者が以前より聞こえにくくなったとのことで、補聴器の需要が増加。
◎6/6は補聴器の日。6を向かい合わせにすると耳の形になり、補聴器販売店の団体の日本補聴器販売店協会と補聴器メーカーの団体の日本補聴器工業会がこの日を補聴器の日と制定。
◎大手通販サイトが聴覚に障害を抱えるモデルを起用。コスモポリタン2021/4/26英国発のショッピングサイトがイヤリング紹介のページで人工内耳をつけたモデルを起用。
◎補聴器で100万円無駄にした人の後悔がニュース 「安易にお店で買わないでまずは病院へ」AERA dot.2021/4/17:本人の聴力状態にあわない高額な補聴器をお店で買わされた事例がニュース。
◎マスク日常化で「聞こえにくい」補聴器の需要が高まる 読売新聞ONLINE 2020/10/25:新型コロナウィルス感染防止の為に人と距離をとる必要が高まり、マスク着用の会話も日常化したことを背景に、難聴者や高齢者が以前より聞こえなくなったと買い求め。オ社は2020年の6月以降、主力機種の補聴器の売上が前年同期の約3倍の水準。
◎人工知能を使用した補聴器の登場:オ社が脳にとって意味のある全ての音にアクセルできるように設計されたはじめて補聴器を販売。これ迄の補聴器の信号処理に関するアプローチを根本的に見直して脳の神経回路を模した人工知能システムのディープニューラルネットワークを採用。脳本来の自然な働きに必要な音の情景の全体像を届ける。
◎イヤホンで音楽を聴いている人が認知症になりやすい「2021/1/15プレジデントONLINE」:順天堂大学医学部附属順天堂医院認知症疾患医療センター長の新井先生の報告では、発症リスクはダントツに多い。
◎2018年8月21日@DIME;耳のスキマの時間を有効活用するということ 「耳活」の時代到来。耳活は脳の活性化そのものである。耳活を情報収集活動として続けていけば、そのまま脳の活性化につながりそうだ。目で読むより耳から情報を入れた方が楽に頭に入るので、耳活は忙しい人の為だけではなく、どんな人にも有用。
◎Yahooニュース 2019年6月15日 11:42配信 GIZMODO:補聴器の未来は、脳波を読み取り音を聞き分けるようになるのかもしれない。騒音下でも、話し相手の声だけは聞き取れるという動きについては、気づかないところで、雑音を消そうとしてくれる脳の働きが関係。このような人間の能力を補聴器にも適応可能かと考えた米国の研究者達が存在。元々先進的な補聴器の中にはWhite除去というものに対応したものもあり、これによって車の騒音等をかき消すことは出来ます。しかしたくさんの人が集まった場所で特定の人の声を聞き分けるとなると、現在のテクノロジーでは難しかったです。コロンビア大学の研究者たちが新たなアプローチを使い、テクノロジーを組み合わせることで、単一の声の音を増幅させる新たなマイクロフォンの設計に取り組んでいるそうです。ニュートラルネットワークを使い、音声処理アルゴリズムが全ての音を拾うことにで、その上で個々の音声のストームに分離。これをリスナーの脳波と比べ、脳の活動状態に最も近い声を自動的に増幅させる為、最も識別しやすくなるというものです。以前の研究では、よく話をする相手の声には反応できても、初めて会う人の声には反応できなかったという課題があり。それをアルゴリズムを事前に学習させることで改良することができた。ただ、いくつかの課題も残り、このテクノロジーが搭載されたウェアラブルの補聴器のプロトタイプが手に入るようになるのは、まだ時間がかかるか。聴覚の障害者を助けることに加え、いずれ音声の認識の向上にも役立つ可能性が秘められています。
◎第46回国際福祉機器展 9月25日から東京ビックサイトにて。全国社会福祉協議会及び保険福祉広報協会主催の第46回国際福祉機器展「HCR2019」は今年9月25日から27日の3日間開催。2019/5/1時宝光学新聞
◎軟骨伝導補聴器「HB-J1CC」 R社と奈良県立医科大学の共同研究により開発・発売した軟骨伝導補聴器「HB-J1CC」はテクノエイド協会が主催する障碍者自立支援機器導入好事例普及事業の中で、技術会H冊研究部門の好事例賞を受賞。2017年11月から販売が開始され、取扱い医療機関で適応と診断された人が購入できる。さらに20歳以下の人が購入する際には「子ども価格」を用意。 2019/1/15 時宝光学新聞
◎みみともコンサート2018:O補聴器(本社・神奈川県川崎市)は社会貢献活動の一環として、難聴者と健聴者、誰もが最上のクラシック音楽を楽しめる「みみともコンサート2018」の開催を決定。演奏者にウィーン・フィルハーモニー管弦楽団の前コンサートマスターのダニエル・ゲーデ氏率いる「ウィーン・ピアノ四重奏団」を迎えて11月2日(金)に東京・銀座の王子ホール(東京都中央区銀座4-7-5)で開催。2018年9月1日・時宝光学新聞
◎O補聴器は、聴覚障害者の案内により、音のない世界で言葉の壁を越えた対話を楽しむエンターテイメント「ダイアログ・イン・サイレンス」に協賛。1998年にドイツで開催されて以来、フランス、イスラエル、メキシコ、トルコ、中国等で開催されこれまで約100万人以上が体験。昨年初めて日本で開催され約3500名が参加。7月29日から8月26日まで新宿ルミネゼロで開催。2018年8月1日時宝光学新聞
◎高齢者・難聴向けに福祉サービスガイドブック:高齢者・難聴向けに福祉サービスガイドブック好評のため増刷 2018年7月15日・時宝光学新聞
◎日本耳鼻咽喉科学会の報告:日本耳鼻咽喉科学会の報告より、おたふくかぜ(ムンプス、流行性耳下腺炎)で2015年2016年の2年間で合併症の難聴と診断された人が少なくとも300人いる。ワクチンは任意接種となりますので、注意が必要です。2017年9月5日・朝日デジタル
◎おたふくかぜで難聴:おたふくかぜ(流行性耳下腺炎)で2年間に難聴が336人も報告される。日本耳鼻咽喉科学会としてはワクチン定期化を要望。
◎産経ニュース 外耳道閉塞症に対しての小型の補聴器が開発。R社と奈良県立大学との共同研究で、軟骨伝導補聴器です。 朝日デジタル 2017年11月30日
◆◆ 耳鳴りとは ◆◆
耳鳴りは、外部に音がないのに、耳の奥で何かが鳴っているように感ずるものと日本随一の辞書には記載されています。蝉の鳴き声のようなジーンや金属音のキーン、高い音のピーなどの音で表現されます。他にはセミの鳴き声やモーター音などで表現されることもあります。英語でTinnitus(耳鳴:じめい・耳鳴り:みみなり)という言葉は、ラテン語tinnreからきているとのことです。日本では、小林一茶や石川啄木も耳鳴りで苦しんでいたようです。
「日本聴覚医学会 耳鳴診療ガイドライン2019」には、耳鳴とは明らかな体外音源がないにも関わらず感じる異常な音感覚と書かれています。耳鳴りは拍動性耳鳴(体内音源・第三者が聞こえる)と非拍動性耳鳴(顎関節症等)と自覚的耳鳴(患者本人のみが聴取可)の大きく3つに分けられます。慢性耳鳴の定義は米国では6ヶ月以上で、独では3ヶ月以上となっています。
◆◆ 耳鳴りの研究の歴史 ◆◆
古代ギリシャ時代の医学の父であるヒポクラテス(紀元前460~370年頃)の時代より耳鳴の研究は行われています。紀元前から研究されているが、未だに「難治」の病です。現代医学でも耳鳴のメカニズムは完全には解明されていません。以前から耳鳴りのメカニズムには4つの仮説がいわれています。
まず内耳でつくられる音に関連した耳音響放射説です。耳鳴りと慢性疼痛の両者の類似点は多く、痛みを客観的に測定できないこと、精神的な状況が関係してくること、ちょっとした刺激に対して過敏に反応してしまうことなどが類似していることより、慢性疼痛類似説というものがあります。耳の中に存在する2種類の細胞のうち、片方に障害が出てしまうことによって耳鳴りが起こるという内外有毛細胞不一致説があります。脳のどこらかに障害が生じた場合、ある周波数の音を聞き取れなくなる状態が続いてしまうと、その周波数に近い音に脳が過敏に反応するようになってしまい、それが耳鳴として聞こえるという神経同調説があります。耳鳴りの高さを測ると難聴になった音の高さと正常な部分との境目で耳鳴がなっていることも多く、この説を支持する根拠ともなっています。
ここ30年の耳鳴りの研究ではMRIを使った脳研究の発展とともに、耳鳴りは音を電気信号にかえる蝸牛の機能低下が耳鳴りの原因という考えから、電気信号が脳に送られたときの反応の問題により脳で耳鳴りがおこるのではないかという考えになってきています。キシロカインという麻酔の注射をすると一時的に耳鳴りが消えてしまうことがある言う現象があります。以前は注射をすると頑固な耳鳴も注射をしているとき、ほんの10秒程度ですが、消えてしまうので治療の一環として行われていました。私も大学院時代に、神経耳科班に属しイノシトール3リン酸の蝸牛における役割を研究しており、キシロカインの作用がイノシトール3リン酸の回路に作用し耳鳴りを抑制するのではないかということで、イタリアのアドリア海側のバーリで行われた世界耳鼻咽喉科学会で発表しましたが、最近の研究では蝸牛という末梢ではなく脳に関係があるようです。
◆◆ 耳鳴りの有病率 ◆◆
日本の補聴器会社が2009年度に実施の「耳鳴りに関するアンケート」では、「事前スクリーニング調査」を実施し、日本での耳鳴り有症率を調査しました。40~70代の世代男女均等割した3,900人に耳鳴り(気になる症状)があるかどうかについて質問した結果、現在自覚症状があると答えた人の合計は全体の22%と全体の5分の1の方が、耳鳴があるとの結果が出ました。日本国内で調べた3,900人のうち、耳鳴の自覚症状のある人を40代~70代男女均等割で416名にしぼり、「耳鳴り」に関するアンケートを実施したところ、耳鳴り自覚者の中でも23.6%の人が常時その音を意識していることが判明しました。年代別では40代が19%、50代が21%、60代が24%、70代が27%の方が、耳鳴りの自覚症状があるようです。年代的に高齢になるほど、耳鳴りを自覚している人が多くなってきているのがよくわかります。
耳鳴りがある方では、23.6%が常時鳴っており、26.4%が過去に経験したことがある、時々鳴るは約半分の50%です。常時耳鳴りが鳴っている方の中で、気になる症状としては、体の事が心配になる人は45.3%、不安な気持ちになる44.2%、イライラするが41.9%、夜眠れないが31.4%でした。あと落ち込んでしまうが14.0%、絶望的な気持ちになるが2.3%といました。このような方は本当に大変だと思います。
耳鳴りのためにイライラしたり、耳鳴りのために体のことが心配になる、耳鳴りのために不安な気持ちになるという方が、耳鳴りの自覚症状のある方の割合の中で約4割苦しんでいるとの報告もあります。
◆◆ 耳鳴りの原因と考えられる病気 ◆◆
外耳の病気として耳垢塞栓や外耳道炎、外耳道膿瘍、外耳道狭窄等があります。中耳の病気として耳管狭窄症、滲出性中耳炎、急性・慢性の中耳炎や真珠腫性中耳炎があります。病気の原因として一番多いと考えられる内耳の病気として、老人性難聴や騒音性難聴や突発性難聴、急性低音部感音難聴、メニエール病、内耳炎があります。他に聴神経から大脳皮質までの中枢系として聴神経腫瘍や脳腫瘍や脳梗塞・脳出血があります。 耳鳴りを起こしている方でこの中枢系の病気を気にする人がいますが、特に耳鳴り症状に変化無く、麻痺や体の変化に異常がなく、数年以内に脳のMRIなどで脳の精査をしたことがあれば可能性はとても低いと思いと思われます。しかし一度もMRIの脳の精査をしたことがなければ、検査をおすすめします。
中枢系で多い聴神経腫瘍(聴神経鞘腫)は脳腫瘍の約7-10%をしめます。比較的頻度の高い良性腫瘍です。30~50歳台の女性に多く発症しますが、男性もかなりいます。聴神経には蝸牛神経(聴力)と前庭神経(平衡感覚)の2種類があり、聴神経腫瘍の殆どは前庭神経から発生します。ほとんどは小脳橋角部に発生します。ほとんどが良性の腫瘍です。他の臓器に転移したり、短期間に急激に大きくなることはまずありません。10万人に対して1人程度と言われています。最近のMRIの発達により、もう少し頻度は多いのではないかと考えられています。 最初の自覚症状多いのは聴力の低下です。腫瘍が神経を圧迫したり破壊することにより、めまいや耳鳴りを発症します。また、腫瘍が大きくなると、顔面神経麻痺や顔面の痙攣や知覚の麻痺を起こします。放置して大きくなると。脳を圧迫してしまい歩行の障害や意識の障害を生じてしまいます。 聴力検査などの検査に加え、早期診断のためにMRIを撮ります。以前MRIを撮り問題はなかったが聴力の低下が持続し、期間をおいて撮ってみたら、聴神経腫瘍だったということも経験上あります。腫瘍が放置されると、大きくなって周囲の組織や神経を圧迫するようになります。MRIのない昔は、発見が手遅れになったり、死因が不明の事例もかなりありました。治療は腫瘍が小さい場合(1cm以下)や高齢者では、まずは自然経過です。聴神経腫瘍のほとんどが1年で平均1-2mm程度しか大きくならないとする報告があります。まず、6ヶ月後、1年後にMRIを撮影し、変化がなければ、その後も1年に1度MRIを撮影し、経過をみます。当院にはこのように何年もフォローアップされている患者さんが多くいます。放射線治療には、γナイフやサイバーナイフと、がんの治療に用いる装置を利用した分割照射法の2つの方法があります。手術には、主に3つの方法があります。耳鼻咽喉科で行う、経迷路法です。これは耳の後ろ側から、中耳内耳を経由し腫瘍を摘出します。脳神経外科が行う後頭部から腫瘍を摘出する後頭下開頭法(後S状静脈洞法)があります。3つめは中頭蓋窩法という、側頭部の骨を取り外し、側頭葉を持ち上げながら腫瘍を摘出する方法です。どれらの手術方法も、患者さんの経過をじっくり見ながら手術方法を選択します。
◆◆ 耳鳴りのメカニズム ◆◆
耳からの音の信号(空気の信号)は外耳道の奥の鼓膜を振るわせたルートと、他に頭の骨の振動のルートが奥の蝸牛で電気信号に変換され、聴神経を伝って中枢に伝わります。中枢経路は、大脳の奥にある脳幹にある皮質下を通り、大脳皮質で音を感じます。皮質下は音をコントロールする役目を担っています。
加齢変化により蝸牛にある耳の神経の細胞が特に高い音に感じる細胞からダメになります。そうすると音を感じる大脳皮質が「あれ、音がこないぞ」とセンサーの感度を上げます。上げすぎてしまうと、音とは違うシグナルまで大脳皮質で拾ってしまい、耳鳴りとして聞こえてしまうのです。高い音が聞こえない人が、ピーという高い音の耳鳴りを聞こえてしまうのもこの論理でちょっと納得がいきます。大脳皮質で耳鳴りがなって感じても、たいしたことなければ大脳皮質のセンサーでとらえることもなくなり、それでは大脳皮質にわざわざ皮質下から音を送ることもなくなり耳鳴りはなくなってきます。
しかし耳鳴りを大脳皮質でずっと強く感じてしまうと、大脳皮質が大脳辺縁系という感情調節機能に作用し「この耳鳴り、いやな感じだなあ」と感じてしまいます。そうすると大脳辺縁系が人間の体の調節機能である自律神経系に作用し、眠れなくなったり、冷や汗をかいたり、緊張してしまいます。人間のストレスは大脳辺縁系と、自律神経系に作用します。ストレスがかかると、耳鳴りのいやな感じはパワーアップします。
従来の薬物治療は、神経自体に栄養を与えるビタミン剤や血流をよくして組織に酸素を与える血液循環剤の他に、うつ病等の精神的な薬を用いて、感情に作用する大脳辺縁系と自律神経系のヒートアップを沈静化して、耳鳴りいやな感じだなあという気持ちを解消させ、緊張をほぐし眠りやすくさせます。軽い運動や好きなことをやることによりストレスを解消することは、薬物療法と同じ大脳辺縁系と自律神経系に作用し、ヒートアップを沈静化して、耳鳴りいやな感じだなあという気持ちを解消させ、緊張をほぐし眠りやすくさせます。
◆◆ 従来の耳鳴りの治療 ◆◆
慶友銀座クリニックでは、慶応義塾大学耳鼻咽喉科学教室(東京都新宿区信濃町)が中心となり行ってきた耳鳴りのお薬の治験を2011年~2013年の間に主に銀座や築地地区の患者様に対して行いました。ネットの検索サイトでも東京都中央区で耳鳴(耳鳴り)を治療してくれるというクリニックを検索すると、銀座・築地地区だけでも耳鼻咽喉科を標榜する慶友銀座クリニックだけでなく内科などの他の科がでてきます。これは耳鳴りは耳鼻咽喉科領域だけでなく、脳神経を含む他の内科的な幅広い分野が関係してくるのがわかります。従来の薬物治療は、慶友銀座クリニックでも神経自体に栄養を与えるビタミン剤(ビタミンB12)や血流をよくして組織に酸素を与える血液循環剤などをまず処方していましたし、症状にもよりますが現在でもまず最初に投与することが多いです。他に内耳組織の血流を改善する目的で星状神経節ブロックや混合ガス治療(健康保険外)というものもあります。混合ガス治療は5%の炭酸ガスと95%の酸素の混合したものを吸入します。二酸化炭素には、血管をひろげる作用があり、中枢に行く血管が拡張し、脳の血流量がアップし、内耳への血流の増加や機能の改善が望めることが期待されます。
他に治療法として耳鳴りに伴う他の症状や病気がある場合には、それを治療して耳鳴りを軽減するというやり方が昔からあります。不眠が伴う場合は眠剤投与、肩や首がこって耳鳴りがあれば、筋肉を緩める薬や頚性神経筋症候群(頚筋症候群)に対しての治療が行われることがあります。スマホが普及してくるに従い多くなっているようです。脳神経領域では片頭痛や群発性頭痛の症状として耳鳴り、他にめまいなども起こしていることもあります。またてんかん関連として脳過敏症の症状のひとつとして耳鳴りをおこしているのではないかという考えもあります。耳鳴り以外にも脳神経関連の症状が出た、これらのような場合は神経内科や脳神経外科とともに、脳のMRIを含めた画像診断や必要であれば脳波も含め検討していく必要があります。他に体全体から治療していくということで、漢方薬を含めた東洋医学もいろいろなアプローチから治療の一つとして考えられています。東洋医学では耳鳴りは、気血の不足により頭部へ滋養が行き渡らない場合に起こるとされています。鍼灸(針治療)は東洋医学ですが、お灸も含めて首や肩周辺の筋肉の緊張をほぐし、血行もよくなり、ひいては内耳組織や脳神経領域への血液循環を促し緊張を解いて自律神経に作用して、耳鳴りの症状を緩和することを期待して行われているようです。慶友銀座クリニックがある中央区銀座・築地地区にも何件か針治療により耳鳴りを治療している施設があるようで、中医学的な針・鍼灸治療による耳鳴り治療も代替療法のひとつとして認識されつつあるのかもしれません。
耳鳴りに対して、うつ病等の精神的な薬を用いる場合は、感情に作用する大脳辺縁系と自律神経系のヒートアップを沈静化して、耳鳴りいやな感じだなあという気持ちを解消させ、緊張をほぐし眠りやすくさせると考えられます。あと従来からいわれている軽い運動や好きなことをやることでストレスを解消することは、薬物療法と同じ大脳辺縁系と自律神経系に作用し、ヒートアップを沈静化して、耳鳴りいやな感じだなあという気持ちを解消させ、緊張をほぐし眠りやすくさせます。
◆◆ 新しい耳鳴りの治療 ◆◆
中国の古典「孫子・謀攻」に「彼を知り己を知れば百戦殆からず。」というのがあります。敵についても味方についても情勢をしっかり把握していれば、幾度戦っても敗れることはないということです。まずは音の聞こえる仕組みをじっくり理解し、どのようにして耳鳴りが発生しているのか、耳鳴りがどうして苦痛なのか、耳鳴りを治療していくメカニズムをよく勉強することが治療の根幹です。耳鳴りの治療の基本である認知行動療法の点からも、耳鳴りとは何なのかということから、耳鳴りの正体をよく学び、耳鳴りを深く理解して治療に望むということは、耳鳴りに対する不安が解消し、病気に囚われている心が解放され、耳鳴り治療のスタートラインと考えられています。
①TRT(Tinnitus Retraining Therapy )
耳鳴り順応療法ともいいます。耳鳴りが気にならない状態にすることを目的とした治療法で、音の豊富な環境を作り出し、耳鳴りを慣らして気にならなくしていく治療法で「聞こえの脳のリハビリテーション療法」ともいわれています。耳鳴りに対して過去にいやな記憶や思い出があると、脳が耳鳴りの音を危険なものと認識します。耳鳴りが続くと、脳が危険信号を出してしまい、悪循環に陥り、耳鳴りの音を脳で優先的に認識してしまうようになります。学生時代にいじめっ子を見かけると、いやな気持ちになりパニクってしまい、続くといやな気持ちになると、いじめっ子をどうしてもクラスの中で気になってしかたがない状態です。いやな気持ち⇔いじめっ子という悪循環になります。TRTはそれを、断ち切る方法です。いじめっ子を避けることなく、にらみ続けることで、⇔を断ち切ります。耳鳴りに似た音を繰返し聞かせることで、本人に耳鳴りに慣れさせる方法です。また他の効果として、大脳皮質で音がこないことによりセンサー感度が高くなっていると、聞こえない音を耳からわざといれることにより、センサーの感度を低くさせ、耳鳴りの感じを低下させます。耳鳴りの感じが減ることにより、大脳辺縁系では耳鳴りのいやな感じが減ります。また耳にわざといろいろな音や大きい音を入れることで、耳鳴りの音を他の音の中に紛らしてしまうことにより、耳鳴り自体を感じにくくなり、大脳辺縁系でも耳鳴りのいやな感じを感じにくくなります。聴力が正常~軽度難聴の患者さんには、サウンドジェネレーター(SG)を用います。難聴の自覚のある中等度異常の患者さんには、補聴器を用います。
適応:耳鳴りの患者さん全てにTRTを施す訳ではありません。以下の症状の患者様は、TRT(サウンドジェネレーターや補聴器)が向いていない場合もあります。耳鳴りの原因として加齢によるものなので、その場合は後で説明する②補聴器による難聴改善方法 又は③心理カウンセリングが有効と思います。
TRTで効果が出にくい方
急性期の難聴(突発性難聴):6ヶ月以上の慢性耳鳴の方がTRTの適応です
重度のうつ病や心因反応:耳鳴りが悪化することがあります
耳鳴りが軽い方:TRTは耳鳴りを消失させる治療ではないので、改善感が乏しい場合があります
超高齢者:機械の操作方法がうまくできない場合がありますので、外来診察時には付き添いの方の同席(ご同伴)をお勧めします
外傷後・交通事故後の耳鳴:他覚的な評価が難しく、当院ではTRT適応といたしておりません
② 補聴器を用いた難聴改善方法
推奨度1A(日本聴覚医学会 耳鳴ガイドライン2019)
ベストセラーの「耳鳴りの9割は治る (脳の興奮をおさえれば音はやむ)マキノ出版」で書かれている、最新の方法です。耳鳴りの権威である済生会宇都宮病院の新田清一先生が書かれました。新田先生は、大学の同じ医局で、大変尊敬しております。
加齢変化で蝸牛にある耳の神経細胞が高音に感じる細胞から劣化し、音を感じる大脳皮質が「音がこないぞ」とセンサーの感度を上げます。上げすぎると音とは違うシグナルまで大脳皮質で拾ってしまい(脳波というぐらい、脳はいろいろなシグナルを発生します)、耳鳴りとして聞こえてしまいます。難聴の部分の音を補聴器を使って補ってあげることで、脳に届く音の刺激(電気信号)を増やし、脳の活性が沈静化し、安定化した活動に近づき、耳鳴りが小さくなるという仕組みです。そこまで難聴はすすんでいないのに補聴器はつけたくないという人がいます。この治療法では、聞こえていない部分の音域のみ、音を大きくして出力するので、これができるのは補聴器しかないので、補聴器を使ってくださいと患者さんには説明しています。
慶友銀座クリニックでは随時耳鳴りの患者さんの診察を行っております。まずはじめに当院の耳鼻咽喉科外来で診察後(全日診療)、後日当院の補聴器外来(予約)での診察となります。
③心理カウンセリング(認知行動療法)
推奨度1A(日本聴覚医学会 耳鳴ガイドライン2019)
うつ病に用いられる認知行動療法は、大脳辺縁系に作用します。耳鳴りの仕組みを患者さんに理解してもらうことで、「耳鳴りって思ったよりたいしたことないよね、そんなに感情が高ぶんなくていいんじゃないの」と理解してもらい、大脳辺縁系のヒートアップを沈静化し、大脳辺縁系が作用する自律神経系の沈静化させます。このことで耳鳴りがなっていても、心も体も気にならなくさせます。
当院では、元慶應義塾大学医学部耳鼻咽喉科の耳鳴外来にて「認知行動療法外来」を指導してきた(国家資格)公認心理師・臨床心理士 中井貴美子先生にきていただき、心理外来(耳鳴:完全予約制)を行っています。
中山貴美子先生の略歴
早稲田大学大学院 文学研究科心理学専攻博士前期課程修了
自律訓練学会評議員、自律訓練法専門指導士
保健指導メンタルアドバイザー養成研修検討委員
東京大学医科学研究所、法政大学講師、慶應義塾大学医学部を経て
松本歯科大学及び慶友銀座クリニックにて心理外来
筑波大学 心理発達教育相談室
(株)フィスメック EAP専任カウンセラー
国土交通省、財務省心理相談員
埼玉県庁、警察庁でメンタルヘルス研修講師
著書
現代のエスプリ「認知行動療法の理論と臨床」-医療と認知行動療法- ぎょうせい2010
30分でわかる初めての自律訓練法」DVD解説書付 フィスメック2012

(参考文献)
2013年第114回日本耳鼻咽喉科学会総会・学術講演会宿題報告 聴覚異常感の病態とその中枢性制御 慶応義塾大学 小川郁
耳鳴りを治す-コントロールしながらうまくつきあう 神崎仁 慶応義塾大学出版会
よくわかる聴覚障害 : 難聴と耳鳴のすべて 永井書店 小川郁編
新田清一、小川郁、井上泰宏、他:耳鳴りの心理的苦痛度・生活障害度の評価法に関する検討Audiology Japan、45(6):685-691.2002
新田清一、小川郁、田副真美、耳鳴り患者の心理状態・生活状況に関する検討 Audiology Japan48(6):617-22.2005
耳鳴りの9割は治る (脳の興奮をおさえれば音はやむ)マキノ出版 新田清一 小川郁
つらい耳鳴り治したいあなたへ 知って、音を使って、治療しよう 監修 慶応義塾大学医学部 耳鼻咽喉科教授 小川郁・済生会宇都宮病院 耳鼻咽喉科診療科長 新田清一
脳を変えて、耳鳴りを治療する 監修小川郁、新田清一/ワイデックス株式会社
つらい耳鳴りを治したいあなたへ 監修小川郁、新田清一/マキチエ株式会社
最新めまい・耳鳴り・難聴 監修小川郁 主婦の友社
スーパー図解めまい・耳鳴り-確実に解消する知識と方法 監修 神尾友信 法研
よくわかる補聴器選び2014年版 監修・著 関谷芳正 八重洲出版
耳鳴り・難聴を治す本 監修石井正則 マキノ出版
聴神経腫瘍患者の初期臨床像 N Matsumoto et al Audiology Japan48-5 p 559-60, 2005-09
聴神経腫瘍症例における耳鳴の性状 : その耳鳴検査・グリセロール負荷耳鳴検査結果について:Tinnitus in Acoustic Neuroma Patients : Results of Tinnitus Test and Glycerol Loading Test A Satou et al.Otology Japan 6-1 63-9, 1996
Effect of tumor removal on tinnitus in patients with vestibular schwannoma: Clinical article K Kameda et al Journal of Neurosurgery. 112(1) p152-7,2010-01.
Long-term effects of tinnitus retraining therapy involving monaural noise generators Inagaki Y, Oishi N, Kanzaki S, Wakabayashi S, Fujioka M, Watabe T, Watanabe R, Wasano K, Yamada H, Kojima T, Shinden S, Ogawa K.Nihon Jibiinkoka Gakkai Kaiho. 2014 Feb;117(2):116-21.
A psychometric validation of the Japanese versions of new questionnaires on tinnitus (THI-12, TRS, TRSw, TSS, and TSSw).Wasano K, Kanzaki S, Sakashita T, Takahashi M, Inoue Y, Saito H, Fujioka M, Watabe T, Watanabe R, Sunami K, Kato S, Kabaya K, Shinden S, Ogawa K.Acta Otolaryngol. 2013 May;133(5):491-8.
Effects of tinnitus retraining therapy involving monaural noise generators.Oishi N, Shinden S, Kanzaki S, Saito H, Inoue Y, Ogawa K.Eur Arch Otorhinolaryngol. 2013 Feb;270(2):443-8.
Influence of depressive symptoms, state anxiety, and pure-tone thresholds on the tinnitus handicap inventory in Japan.Oishi N, Shinden S, Kanzaki S, Saito H, Inoue Y, Ogawa K.Int J Audiol. 2011 Jul;50(7):491-5.
Repetitive transcranial magnetic stimulation (rTMS) for treatment of chronic tinnitus.Minami SB, Shinden S, Okamoto Y, Watada Y, Watabe T, Oishi N, Kanzaki S, Saito H, Inoue Y, Ogawa K.
Effects of selective serotonin reuptake inhibitor on treating tinnitus in patients stratified for presence of depression or anxiety.Oishi N, Kanzaki S, Shinden S, Saito H, Inoue Y, Ogawa K. Audiol Neurootol. 2010;15(3):187-93
An early work by Dr. Jastreboff presented in France in 1991 about his creation of an animal model.Jastreboff, P.J., Brennan, J.F. Animal model of Tinnitus: Recent Developments. Tinnitus '91: Proceedings IV International Tinnitus Seminar, Bordeaux, France 1991.
An important summary of work on the animal model.Jastreboff, P.J., Sasaki, C.T. An animal model of tinnitus. A decade of development. American Journal of Otology, 15:19-27, 1994.
Moving into evaluation of loudness in the animal model.Jastreboff, P.J., Brennan, J.F. Evaluating the loudness of phantom auditory perception (tinnitus) in rats. Audiology, 33:202-217, 1994.
Important work on the animal model.Jastreboff, P.J., Brennan, J.F., Jastreboff, M.M., Hu, S., Zhou, S., Chen, G, -D., Gryczynska, U., Kwapisz, U. Recent Findings from an animal model of tinnitus. Proceedings of the 5th International Tinnitus Seminar, Portland, Oregon, 1995. American Tinnitus Association, Portland, Oregon.
A good resource for audiologists. Jastreboff, P.J. Instrumentation and tinnitus:A neurophysiological approach. Hearing Instruments, 45:7-11, 1994.
A paper describing the use and fitting of the NGs.Gold, S.L., Gray, W.C., Jastreboff, P.J. Selection and fitting of noise generators and hearing aids for tinnitus patients. Proceedings of the 5th International Tinnitus Seminar, Portland, Oregon, 1995 (available from the ATA).
まず耳鳴りとしてキーンと鳴ることがあります。特に夜寝る前に、特に静かな部屋で鳴ってしまい寝られないという人がいます。キーンと鳴るのは、原因として難聴がある場合があり、特に高音部が聞こえないと、高音部に似たような音が耳鳴として聞こえることがあり、キーンという音として聞こえることがあります。聴力検査をやってみて、どの音が聞こえていないかを精査してみることが必要です。またティンパノグラムという鼓膜の状態を調べることもあります。他には耳管機能検査が必要な場合がありますし、状態をみて耳のレントゲンやCTや脳のMRIを撮ることもあります。これらの検査をして難聴の状態と、鼓膜や鼓室の状態を調べ、急性中耳炎・滲出性中耳炎や耳管開放症を精査します。状態によっては鼓膜を切開したり、チューブをいれることもあります。突然なった場合は、音響外傷や突発性難聴による聴力障害が原因のことがあります。
その場合はまず安静にした上でステロイド投与が必要なことがあります。
飛行機の中や、エレベーターでも特に降りるときに多い、耳に不快な「耳がキーンとなる」現象があります。高低差で耳がキーンとなるのは、気圧の変化によるものということは良く知られています。気圧の変化で耳がキーンとなりやすい人は、鼓膜の内側にある中耳と鼻の奥とをつなぐ耳管(Eustachian tube)の機能が不全の場合があります。
慶友銀座クリニックのある銀座・築地及び周辺の勝どきや晴海地区では、超高層ビルが建ち並んでいます。超高層ビル、特に超超高層ビルで仕事をする方、または住んでいらっしゃる人に、耳がキーンとなるといって来院する患者さんが多いです。ものすごいスピードで、エレベーターは動いているようです。地上は厚い大気の層の底にあり気圧が高いです。
しかし上に行けば行くほど空気は薄くなり気圧は当然低くなります。エレベーターで瞬間急に高いところに行くことにより、耳の内部つまり鼓膜の奥の気圧はすぐには変わらないので、鼓膜の外と気圧差ができてしまいます。つまりエレベーターが上昇したときなど、鼓膜の中の気圧は、鼓膜の外(体の外・エレベーターの中の気圧)よりも高くなります。すると、鼓膜が外に膨れるようになり、鼓膜がうまく振動できず、鼓膜と鼓膜の奥の耳小骨の連動が悪くなり、音が伝わりにくくなり、耳が詰まったようなキーンとした感じになります。さらに下降する際には逆に耳の内側の気圧が低くなり、鼓膜が内側に引っ張った状態で、これまた鼓膜と耳小骨の連動が悪くなり、音が伝わりにくくなり、それが、耳がつまったような感じになってしまい、耳がキーンとしたり、耳の中が痛くなったりします。耳管は鼓膜の内外の空気圧を等しくするという圧力調整をしています。人間の耳管は、頭の左右のほぼ同じ位置に1対ずつ存在し、形状は年齢ともに変化するようです。鼓膜の奥の鼓室の下部より、鼻の奥の鼻咽頭腔(上咽頭)へと続いています。ところが、耳管に空気が通りにくいと、耳がキーンという耳づまり感がでやすくなります。つばを飲み込むと耳管が広がり、鼓膜の内側と外側の気圧を調節できて音が消えます。耳管に空気が通りにくい原因として、まず鼻の通りが悪いことがあります。鼻中隔弯曲症や鼻副鼻腔炎、鼻ポリープやアレルギー性鼻炎、気管支喘息が関係する好酸球性副鼻腔炎があります。他には上咽頭にあるできもの(腫瘍)です。
また膠原病等の病気により、唾が減っても当然なりやすいようです。
飛行機でキャンディーのサービスがあります。日本の航空会社ではありますが、海外の航空会社では結構ないので院長はキャンディをもっていっています。キャンディをなめると唾が出ます。耳詰まり、キーンの防止のためにキャンディを配っているのですね。でも中には黒砂糖キャンディのような直ぐ溶けるのが入っているので、できれば溶けにくいのを選ぶといいでしょう。しかし子供さんは、キャンディを食べながら飛行機の中で眠ったりして、誤嚥したり、気道につまったりすることがあるので、キャンディをあげるのはやめてください。エレベーターの中ではキャンディをなめる暇はありません。ゆっくりと動いてくれれば体も対応できるのですが、ものすごいスピードだと体が反応しません。中国大陸では上海をはじめ、ものすごい勢いで超超高層ビルができているそうです。中国の方はウイルスの関係で、上咽頭という鼻の奥と耳管の間にある場所に腫瘍が多いという報告があります。当院でも耳がキーンとなる、飛行機に乗ったら中耳炎によくなると訴える、特に中国系の患者様に関しては、特に念入りに上咽頭を内視鏡等をつかって精査し、腫瘍をみつけることがありました。中には日本人の中でも上咽頭の悪性リンパ腫をみつけたこともあります。上咽頭の腫瘍は、耳鼻咽喉科だけが精査することができますので、心配な方はまず耳鼻咽喉科にいらしてください。このような経緯から、中国の方でどうしても超超高層ビルで仕事ができないとか暮らせないという人の中で、耳鼻科に行ったら腫瘍がみつかったということもありそうです。超超高層ビルで仕事するように又は暮らせるようには、人間の体のつくりは想定されていません。特に上咽頭にうまれつきあるアデノイドという組織がまだ大きい子供さんは、耳管の形状がまだ未熟なこともあり、顔も頭も小さく、鼻炎も潜在的に多いということもあり、エレベーターのスピードについていけない場合もあるようです。エレベーターのスピードを速くすれば速くするほど、メーカー的にはエレベーター内の圧力を速く調節するのでしょうが、本当に速く調節できるのか、人間が対応できているのか、子供は大丈夫なのか、研究の余地がありそうです。将来的には、何種類かスピードの違うエレベーターが必要とされるかもしれません。以前ロンドンの古い古いホテルに泊まったことがあります。5階の部屋に行くのに、中はかなり大きいスペースでソファがあるエレベータを使いました。中国の国家主席の習近平も一週間前乗ったと、エレベーターボーイのおじいさんがいっていました。ゆっくり座って、少しずつ動くエレベータでなので、習近平も耳がキーンとなることはなかったでしょう。山の上の天守閣で殿様が采配をふるっても、えっちらおっちらお城の上に登っているだけです。もし将来的に超超高層ビルでお仕事をする予定があるかた、暮らす必要がある方、またはもう仕事をしたり暮らしたりして調子の悪い方は、まず是非耳鼻咽喉科にいらしてください。聞こえや鼓膜の状態及び耳管周囲の状態を精査し、これから仕事をできる状態か暮らしていける状態か精査します。
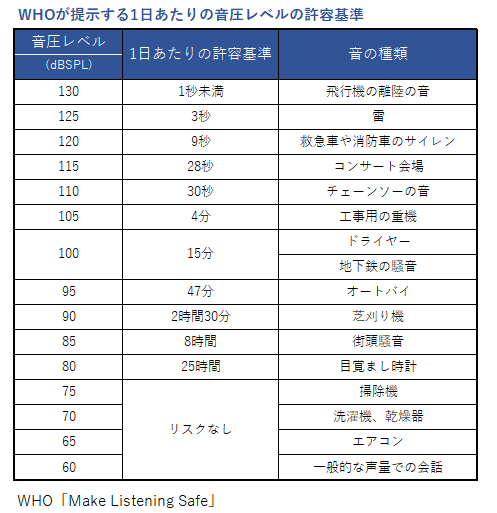
世界保健機構WHOは、世界の11億万人の若者達がスマートフォンや携帯型音楽プレーヤーなどの音響機器の利用や、イベントでの大音響により深刻な難聴のリスクにさらされているとの報告をしました。85デジベルで8時間、100デジベルで15分を越えると危険とのことで、音量の低下や、連続して聴かないで休息をとる、日常のスマホなどのオーディオ機器の使用を1日1時間までに制限することなどが勧告されています。(参考 下記参照)85~90デジベルより小さい音であれば、耳を痛める可能性が低いと考えられています。電車の中で、イヤホンから音漏れしてうるさい場合は、まず90デジベルを超えている可能性が高いです。90デジベルはカラオケの店内の音の大きさです。まず長時間聴くのをやめましょう。休肝日ならぬ休音日(イヤホンやヘッドホンを使わない日)をできればつくりましょう。1時間聴いたら、まず1時間耳を休ませることが大切です。
参考
http://www.who.int/mediacentre/news/releases/2015/ear-care/en/
https://www.japan-who.or.jp/event/2015/AUTO_UPDATE/1503-1.html
近年、音楽プレイヤーやスマートフォンによる大音量での音楽の再生や交通騒音、レジャーでの騒音が、「ヘッドホン難聴」や「イヤホン難聴」、「耳鳴り」の発症リスクとして問題となっています。
特に10~30代の若者内で広がっており、できるだけ耳に負担がかからないよう、生活上の注意を患者さんに呼びかけることが大切です。
● 音楽や動画を視聴する際には、適切な音量を心がける
● 騒音下で仕事をする際には、耳栓などで耳を保護する
● 環境騒音(交通・レジャー騒音など)に対する認知を広げ、注意する